
Devrims #TechTalk037: Federico Razzoli, Founder of Vettabase, Talks About Databases

This time on Devrims TechTalk, we have Federico Razzoli, Founder of Vettabase. Federico loves databases. So much so, he wrote a book titled Mastering MariaDB nearly a decade ago. But, he likes MySQL too and he started his career as a MySQL Database Admin (MySQL DBA).
This interview is packed with great advice about database optimization, cloud cost optimization, and data management. However, to witness how passionate he is about databases, you should look at the answer of the last question in this interview.
Devrims: Thank you for your time, Federico. Can you tell us about your background and how you got started in the field of database management and automation?
Federico: In my whole career, I worked with databases. In the very early days, I was a web developer. Then I worked at a couple of projects that involved working intensively with databases. So I realised that, while I liked coding, I liked databases even more, and I quickly became a MySQL DBA. After several other work experiences as a DBA or as a database consultant, I finally started to work at Catawiki, where I was the only DBA. The number of servers to manage wasn’t impressive, but it was a bit too much to do everything manually. And fortunately, my manager was obsessed with automation and the DevOps culture. This made me learn a lot. I didn’t realize this for a while, but in my next job experiences, I tried to automate database operations as much as possible.
Devrims: What inspired you to start Vettabase and specialize in database automation and management services? What problems were you looking to solve?
Federico: As I mentioned, at some point in my career I got fascinated with automation. Later, I became a freelance consultant, and then I started Vettabase.
The idea was helping companies, especially growing startups, with the common problems that they typically have. Having worked almost exclusively with startups, I knew those problems quite well.
The problems of a startup can be easily explained. In their early stage, they need to build a product as quickly as possible to make investors happy and gather more money. They don’t have the time, nor the competencies, to build a solid, highly scalable, and beautifully designed application. And they don’t care too much, or they could never manage to pass that first stage.
But then they start to grow, their user base expands, more functionalities are added to the product, and users have higher expectations. The business works great, but the technological layer simply can’t keep up.
Databases are the most critical part of an IT infrastructure, and usually the slowest. Here is when we can step in and provide great help! To improve performance, we optimize database schema and configuration.
Devrims: How can automation and infrastructure-as-code techniques help companies manage databases more efficiently?
Federico: Thanks for this great question!
You can see any deployment, upgrade, backup, and more as a sequence of things to remember and commands to type into the terminal. While this can be neat, but also slow and error-prone.
People’s hours have a cost. Mistakes we make have a cost. The time to fix them is the most obvious cost. If the mistake makes it to the production environment, more costs might be paid in terms of slowness, inefficiency, incidents, maybe even data loss or security breaches. There are studies that demonstrate how slowness can induce a relevant percentage of users to leave our website, and some will never come back. This is the most important class of costs, and it’s a pity that typically companies don’t measure it before setting budgets for the new year.
Now, automation can be made in many ways. Our preferred automation technology is Ansible, but any famous alternative is also great and absolutely valid. So, choose whatever your team already knows of likes if you wish, but please, please, please automate your operations, including database administration.
Devrims: Could you share some examples of clients where your database optimization services and expertise measurably improved their infrastructure?
Federico: I’m afraid I can’t mention customers without their permission. However, on Vettabase’s website, you can find some customers’ logos and a case study for one of our most loved customers, Treedom.
Long story short: we provide continuing support to their Aurora clusters, and we maintain their ProxySQL image that runs on Kubernetes. They never had a database incident since they were with us. They saved 40% of database infrastructure costs. We automated their database operations and trained some developers.
Devrims: Let’s do a quick rapid-fire question.
| Devrims | Federico |
| Traveling or Staying Home | Traveling, but flight experience got so much worse in recent years. |
| WFH or Onsite | Both, with the right balance. |
| Tea or Coffee | Home-made espresso! 🙂 |
| MariaDB or MySQL | I and most of our customers prefer MariaDB, but in some areas, MySQL is better. |
Devrims: If you had to choose one database management tip that every organization should implement immediately, what would it be, and why?
Federico: Test your database backups. This task, more often than not, is overlooked. This leads to unusable backups. GitLab had a famous database incident in 2017: they deleted some data accidentally and needed to restore a backup. They had three backup strategies in place. But none of them were regularly and automatically tested, so none of them were working. You don’t want to be in the same situation. Data loss has a cost, and many companies just can’t afford it.
Devrims: Security is a paramount concern when dealing with databases. What measures should anyone take to ensure the security and integrity of clients’ data?
Federico: Connections to the database servers should only be allowed from a group of servers. Human users can use a jump host or an SSH tunnel. On cloud infrastructures, this can be done using security groups.
Both applications and human users should only be allowed to establish SSL connections to the databases.
A data-at-rest solution is often important, too. We tend to rely on cloud vendors and data centers, but we shouldn’t forget that human beings work in those data centers. If our data has a big value, those persons might steal and sell a physical storage device containing our data.
Finally, don’t forget that each database user should only have appropriate permissions. A data analyst shouldn’t be able to delete or modify data, and a regular application user shouldn’t be allowed to drop tables. This will prevent attacks from corrupted employees, as well as external attackers that might take advantage of application bugs. Database permissions are generally complex, but we can use roles to make them easy to maintain.
Devrims: Scalability is crucial as businesses grow. How do you assist someone in scaling their database infrastructures effectively?
Federico: First of all, we strongly advise the customers to let us optimize their queries, schema design, and database configuration. Some performance problems can’t be optimized by just adding one node and some of them will actually get worse. But even if scaling out in your case is a universal remedy to all problems, do you really want to waste your money by having many instances, all of which use many more resources than it should use? Obviously, it’s not an ideal situation.
The next important point is that the application must be written in a way that allows the database to scale. The code that interacts with the database needs to distinguish between three types of SQL statements: writes, reads of the most recent data, and potentially stale reads. These connections should be run by different database users. That’s all the application needs to know.
Then, we set up a high-availability solution. The choice depends on the customer’s needs.
If it’s a solution based on synchronous replication, typically all writes are sent to the same node, and reads should normally be sent to the other nodes. In this way, there are no possible conflicts when data is written, and reads can typically scale well.
Asynchronous replication solutions can be used on top of that, to add further scaling capabilities and redundancy, or as the only high-availability solution. It’s important to remember that asynchronous replication normally replicates data with a slight delay, and for some critical use cases (typically payments) this is not acceptable. Normally there is no guarantee that this delay won’t be of hours or even days, but in that case, it’s possible to redirect the queries to the most updated replicas or, as a last resort, to the master.
The logic that decides which SQL statements will be directed to which server can be fairly complex, and needs to keep into account factors such as transactions in progress and usage of temporary tables. This is delegated to some type of load balancer that needs to be configured correctly and periodically tuned.
While I hope that I answered your question from a technical perspective, the first part of my answer is the most important. And it’s not really technical, it’s mostly cultural. A good scaling is only possible if the development team understands the problems of database scaling.
Devrims: How do you manage or overcome writer’s block?
Federico: Well, I’m not a professional writer. Sure, I write a lot of marketing content for our website. But I do it when I have something interesting to talk about a new version of a DBMS, a new feature, or a problem a customer faced. So I never have writer’s blocks.
Devrims: What were the key contributions and insights from your book, Mastering MariaDB, published in 2014, during your time as a MariaDB Community Ambassador?
Federico: To be completely honest… if I rewrote that book nowadays it would be structured very differently. Plus, MariaDB evolved a lot since then. But some people gave me good feedback, both privately and publicly. So, despite my self-criticism, apparently, it helped people to understand the mechanisms of the InnoDB storage engine and Galera Cluster. I’m a fan of sharing knowledge and teaching, and that could be one of the reasons why I always preferred open source.
Devrims: Who would you recommend us to interview next?
Federico: Since you’re a managed cloud hosting company, I recommend my pal Lauren Nadolson, a product manager at cPanel.
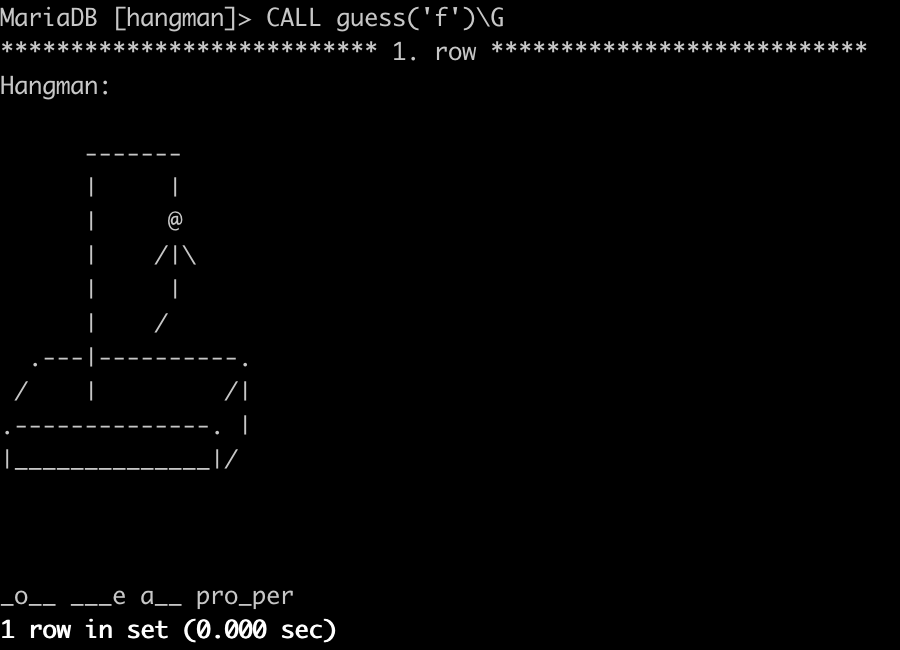
Devrims: Lastly, would you mind sharing a glimpse of your workstation?
Federico: If you don’t mind, I’d like to share this instead! It’s an ASCII game I wrote some years ago, using MariaDB stored procedures. I’ve done it only for fun. I found amusing the idea of playing hangman from the MariaDB command line client.

Related Tutorials




Devrims #TechTalk 071: Deryck OE on Mastering WordPress and Laravel Development

